WWDC Wish List: tvOS
As we get closer to WWDC, I notice that there’s a dearth of excitement, interest, or rumors in anything involving the Apple TV. It’s hard to blame anyone for the disinterest since the platform hasn’t really wowed anyone since its premiere and no major rumors have circulated in advance of Monday’s event. I’ll run through a list of things I would like to see, though I myself am skeptical any of them will materialize in a few days.
Darker Interface
The team that designed tvOS valued light, open, bright designs. Unfortunately, in a dark living room, this is rather harsh on your eyes. This is something that the previous generations of the Apple TV had right, and I’d like to steer back toward it.
Picture in Picture
PiP is a fairly old concept, and not necessarily an exciting one. A video plays in a little box and other videos, or graphics, are available elsewhere in screen space. I don’t really wish for arbitrary video boxes to float around the interface, but there are many cases where the user experience could be improved by allowing a video to float while you navigate some menu hierarchy for another video to watch. The Apple TV is not really a snappy-multitasker, so offering that foothold into what you were watching while you look for something else would be very handy. As Jason Snell points out in a piece for Macworld, some apps even implement their own PiP to display multiple things, like the Major League Baseball app displaying multiple baseball games.
After all, PiP is a feature that came to iOS before tvOS, and tvOS is built on iOS … and iOS borrowed the idea from TVs … so it’s not the worst idea. It also happens to be a building block for more complex interactions like…
Interactive Programming Guide
I know you think I’m abusing an addictive substance, but let me assure it’s just pinot noir. Interactive programing guides are a familiar sight to anyone that’s used a TV in the last 20 years. An interface is presented to the user that’s like a spreadsheet, with a table of times, and channels, and what is currently playing on them. Most of these programming guides also embed the video that is currently being viewed so that people can browse the list of channels while still watching their show (either with the intent to switch channels, or to merely check information).
I’ve been trying to pitch this to people since last fall and no one is biting, but here me out, and bite away. The Apple TV actually does have “live” TV programming in some apps, but it’s totally invisible to the system, and to the user, unless that feed for that particular app is open and playing. This is ridiculous in 2016 because it makes channel surfing into some kind of investigative reporting simulation. You have to pop open each app that offers a live stream, then navigate to it, then open it and wait for it to load whatever might be playing. It’s hardly like hitting channel up, and channel down. This is a problem that TV solved decades ago, and it wasn’t even this slow for a TV to change channels.
Before the wave of skepticism pulls me out to sea let me assure readers that human beings do watch live, and “live”, video on TV by the millions. Live video is so important that YouTube, Facebook, and Twitter are all trying to get in on it. Just because “live TV” conjures images of CBS crime procedurals for you doesn’t mean that’s the case for everyone.
Apple could offer a mechanism for an installed app to register that it offers live video, and to detail what the programming for that live video is. Only the applications that are installed would be present, and their programming viewable while watching another video stream. Potentially you could even ask Siri “What’s on?” to pull up the guide. Or ask “When are the Oscars on?” and get that familiar, linear bar of what’s available.
Let’s not forget that “live TV” isn’t typically live, it’s just an linear stream of shows and ads set to play at given times. That linear stream is a useful way (but not the only way) for people to find new shows thanks to the serendipity of turning on a TV during a certain time slot. Techies might scoff at such notions, but … like it’s a thing.
AirPlay(3)
There’s an incredibly irritating and very persistent bug (series of bugs?) with AirPlay where playback is interrupted and the stream is kicked back to the device it was streaming from. This occurs with a great deal of regularity, but AirPlay is still the best way to get audio and video to play in my living room in spite of it.
I hope that Apple has a more robust solution for AirPlay going forward that doesn’t flake on an all-Apple-device network.
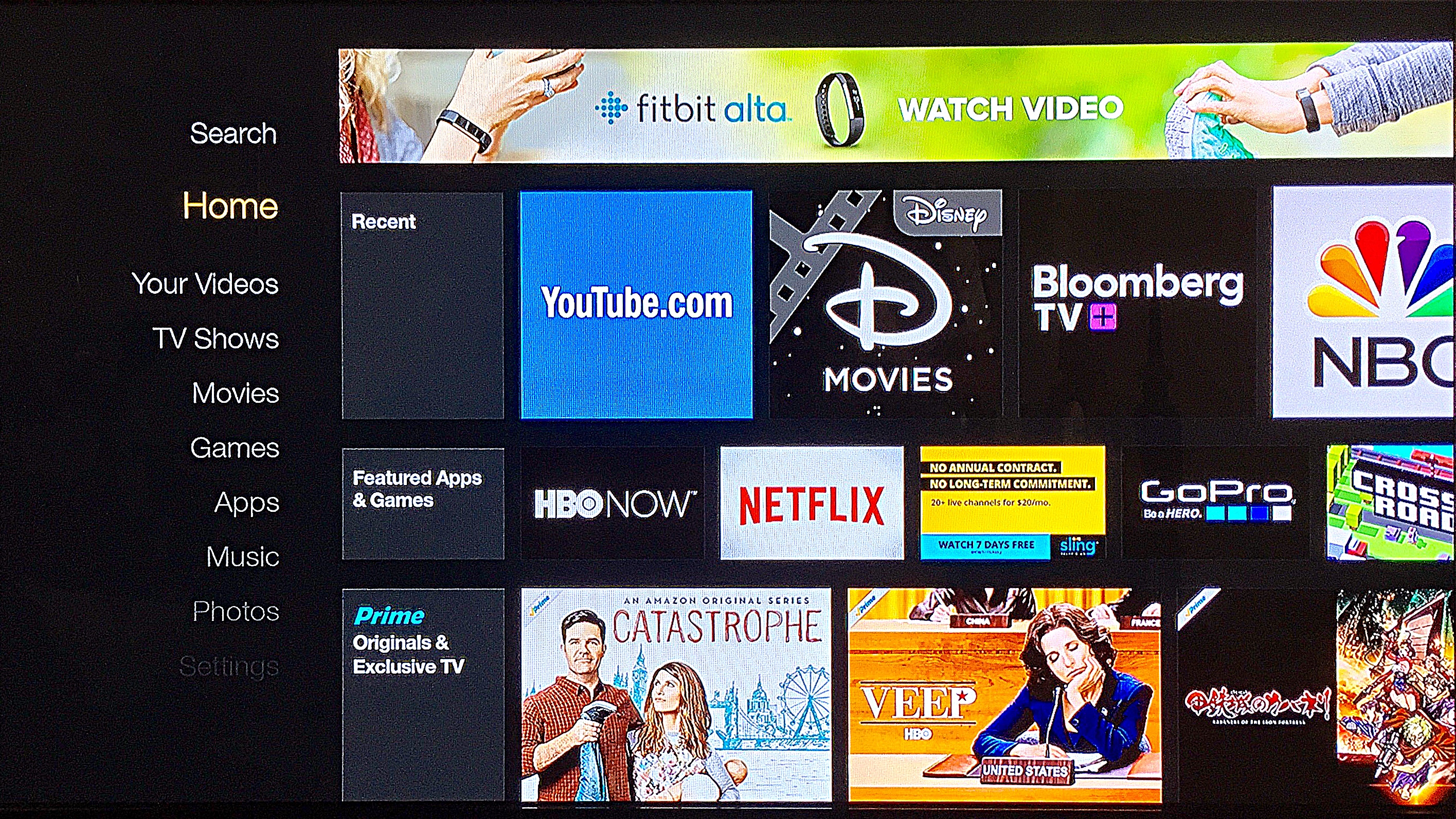
A New Multitasking View
The original multitasking view for tvOS was a flat series of cards with excessive gaps between them. It presented a thumbnail view of what the app had last displayed. In the updates since launch, Apple revised the multitasking view to appear more like the iOS view. This is unfortunate because I have an enormous screen dedicated to showing me one card and the edges of two other cards, with a very blurry card in the background.
If the apps I’m switching between are TVML apps, then they look almost visually identical so you’re really looking at the name, and icon, which are in the top of the screen and take up the least amount of space. The multitasker only displays a single app title at a time as well, so all the blue and purple gradients really stick out. If the system has been restarted (either by the owner, or by the system just doing its thing) then the thumbnails for the apps are also medium-gray rectangles.
This is not suitable for me and I almost always switch apps by going back to the homescreen because it seems faster to mentally sort it.
I hope that there’s a new multitasking view that takes advantage of the screen real estate, and PiP, to allow me to move fluidly between applications and not between individually displayed, static rectangles.
Turn Folders Into Page Breaks
When I heard the rumor that folders would be added I laughed pretty hard. When I saw folders were added I let out a big sigh. Whatever is going on with the management, and development, of tvOS post-launch seems to be heavily skewed towards metaphors that work on iOS. Folders are implemented almost the same way where you hold down the touchpad until the parallax-icon wiggles, then you drag it over another icon and let go. It opens up a vast, white void where those two icons now live. This is… un-TV-like, and an inefficient use of screen space, and my tapping.
What I wish for is the ability to add a dividing line in the homescreen. Category dividers that section off the way apps are organized but leave the icons at the same size and don’t require “opening” and “closing”.
Amazon uses a category system in their Fire TV interface, which is not flexible for the user, but doesn’t burry things. The Amazon way of doing thing relies on the system to populate the app across multiple categories too, even in “recommendation” sections. This seems very, un-Apple-like, so I’d settle for a series of dividing lines and apps inside of them.
Take advantage of that ridiculous remote and let me exert extra swiping-force to move from line to line. News to Movies, etc.
Aliases for Content
The system doesn’t provide a way for people to directly access a favorite show in Netflix right from the home screen. There’s no way to bookmark something you’re interested in, and pin it right to the homescreen as if it were an app. Amazon treats content like apps on the Fire platform so they can mix movies, apps, music, games, and TV shows all in the same interface. Apple only presents the top-level of every app and nothing else.
Overhaul the TV Shows App and the Movies App
These apps are strongly geared toward someone buying/renting a video that is advertised to them as soon as possible. They are pretty unfriendly toward people that want to watch something that isn’t new. In the Purchased tab of the TV app, there’s a grid of shows, displaying a tile of artwork for the current season of that show. There aren’t any visual indications of what you’ve watched already, or what you were last watching when you used the app. Each show also arranges episodes as a series of narrow, horizontal tiles that needed to be scrolled through to get to what you want. I wish they overhaul this navigation.
The Movies app offers some sorting options by genre, but not by when you watched something. Also the genres are from the iTunes store and each movie gets a single genre designation. This is a problem if the designation isn’t right. The first six Star Wars movies are listed under “Action & Adventure” but “The Force Awakens” is listed under “Sci-Fi & Fantasy”.
These apps exist under the Videos app on iOS, and the iTunes App’s TV and Film sections on the Mac and PC. None of it is consistent.
Non-tvOS App Store Purchases
I want a unified storefront where I can buy an app on any of Apple’s platforms, even if it isn’t for the one I’m currently on, and push the app to any, or all, of my devices. Google and Amazon have solved this problem years ago. Apple currently bounces you around between several redirects before you land on some rather unhelpful pages. Then you can take that result, remember it until you get home, and ask Siri to find it in the App Store for the TV. It’s like sharing apps with semaphore.
Initial App Setup
When you fire up the device there is a very minimal homescreen. Opening the App Store initially shows a bunch of suggested apps. There’s also the “Purchased” tab which displays apps that the iTunes store backend knows that you’ve purchased, or “got”, on other devices and can sort the information by “Recent Purchases”, “Recently Updated”, “Not on This Apple TV” and by the App Store category the app is listed under.
This is very helpful, except there’s no “Download All” feature, and each app icon must be individually clicked on to bring up the info for the app and then download it. Then back to the menu. It would be nice to very quickly populate an Apple TV.
Unified Credentials with iCloud Keychain
I don’t want to sign in, or verify, every app that I download. Especially not if the TV version of the app has a companion app on my iPhone, or a website I logged into with Safari. Frustratingly, Apple already has a tool for this with iCloud Keychain, but it’s not used to unify this. Instead you’re entering codes from your TV into URLs on your computer — like an animal.
I’ve also seen a lot of Apple fans say that Apple doesn’t do this BECAUSE SECURITY but if that were the case than iCloud Keychain wouldn’t store my credit card info across devices on Apple’s severs, let alone what kind of video subscription services I have access to.
What to Watch
In the tvOS App Store, the “What to Watch” section features video steaming apps. Those apps are almost exclusively apps that require a cable, or satellite TV subscription only. I wish this section was devoted to apps for people that did not have cable and satellite subscriptions. That might make the area look pretty sad, but it would reduce the amount of investigative work I have to do.
Remote
The remote is still a frustrating instrument that should be outlawed, but it’s not going to go anywhere at WWDC.
Drag and Hold to Continue Movement
One of the more annoying aspects about using the remote with the interface is that the remote’s touch area is very narrow, but the swipe required to move between interface elements requires dragging from the center of the pad out toward the edge of the pad, then lifting your thumb back to the center of the pad and starting over.
Back when Marko Savic and I used to regularly podcast about the Apple TV this issue was discussed, and Marko (I think?) suggested a persistent drag, just like when you’re moving the playhead in the timeline in a video view on the Siri Remote. Siri would keep going in the direction your thumb moved, while you held your thumb on the edge of the touchpad you had hit. To stop, lift the thumb, or move the thumb back to center like an analog stick on a game controller.
I speculated that Apple probably didn’t want to do this because then no one would appreciate the Parallax Icons — I would gladly burn the Parallax Icons to the ground in exchange for non-repetitive thumb movement.
iOS Remote App
Apple was rightfully lambasted for completely skipping support for anything other than the Siri Remote. iPhones, especially ones released around the time of the 4th generation Apple TV, are far more sophisticated than the $80 glass and metal remote. Only the old, crappy app is supported right now, but Eddy Cue has announced a revised Remote App will be available this summer.
Games
Release a controller. Apple knows that they should. Every Apple Store I’ve been in has Nimbus controllers (plural) next to the Apple TV demo unit. The Siri Remote is better suited to stirring fondue than it is playing games. Perhaps the new iOS Remote App will be a decent controller, but there’s no real excuse for Apple to support the Steel Series Nimbus so heavily and abdicate any first-party responsibility for making a game controller, or insisting that games be playable on the Siri Remote.
The crappiness of the gameplay is a large reason I abandoned even trying to play games. If Apple would like to acknowledge that games are a traditional revenue source for them, then it would benefit them to make games something that people want to play.
A Message for the 64 GB Model
Right now, Apple’s stance is that you should buy the 64 GB model if you’re going to play a lot of games. That’s … not enticing. On tvOS, the app storage is capped so the storage seems like bizarre overkill. There really should be a narrative for why this model exists. If they’re going to allow record of live broadcasts, or preemptively buffering movies you’re watching, or buying, on other devices, than this starts to make a little more sense.
Streamlined Apple ID and Apple ID Switching
There’s an “Accounts” subsection of the “Settings” app in tvOS which details the 4 places where the same, exact account is signed in. Why? iCloud, uTunes and App Store, Game Center, and Home Sharing all have separate Apple ID logins. Clicking on iCloud gets you three different photo-oriented toggles: iCloud Photo Library, iCloud Photo Sharing, and My Photo Stream.
There’s also an option to “Manage Subscriptions” which will bring up the reviled horizontal keyboard and ask you to sign in to see what you’re subscribed to (something that might be given away by what apps are installed???). If you decline, that brings up an endless spinner (hit the menu button if you do this), because that’s not an expected behavior. Every time a login screen pops up, you should enter passwords and login info.
This is a TV let’s get a grip. There should be a single sign in, sign out, and switch user system. If holding a iPhone near a TV can let me set up my TV, why can’t I authorize it to jump to my account, or a guest authorize it to jump to their account? I wish this was a single profile that followed me, and not a series of separate wires that needed to be defused in the correct order.
Backup and Restore
I’ve been bothered by the lack of a backup and restore system since the launch of the platform. Not because I do that regularly, but because I know that I will eventually need it. Why can’t I setup a second Apple TV (other than I’m sane) that restores the same state as my first Apple TV? What happens if I need to replace this device because of a defect, or theft? What happens when I go to upgrade this Apple TV to the next model in X years? I have to setup everything from scratch again. I wish it weren’t the case.
Siri
There are several rumors about a major update to Siri, and a Siri API. I would hope that Apple plans on rolling out a consistent experience across all their devices, including the TV, and that Siri commands given to one device can affect your other devices you’re logged into. Like if I tell my phone I want to watch something on my TV, it should be able to show it on my TV. Google showed a concept video where their Assistant understood the context of questions and the devices it had available to it.
Due to the importance of Siri on the device, and Siri on all Apple’s devices, I feel pretty confident we’ll at least see improvements there, and it only makes sense for those improvements to be across the various Apple platforms.
I’m looking forward to WWDC because I imagine it will be a jam-packed update-stravaganza. I do hope that there’s something exciting in there to make my $150 Netflix box fell like a delightful component in my living room.
Category: text







{kind=link}
{kind=link}