Disney (DIS -1.18%) alone lost 6% of its value, ending at its lowest level in six months, and has now lost more than $30 billion in market cap in a little over two weeks. Time Warner (TWX -1.62%) was also down about 5%, to its lowest level in 2015, and 21st Century Fox (FOX -2.65%) was down a little over 4%. CBS (CBS -2.04%) and Discovery Communications (DISCA -0.81%) were both down by about 5%, and Viacom (VIA -0.95%) dropped by more than 6%.
The stocks recovered a little bit today but they’re all still down.
The analyst comment that set this all off:
“The market is now valuing U.S. ad-supported TV businesses as structurally impaired assets,” Juenger said. “We believe this is fair and warranted, because: a) we believe TV advertising is undeniably in secular decline; and b) affiliate fees are now also being put at increased risk. When an industry is undergoing a massive structural upheaval, one major revenue stream is already impaired — and now there are signs the second one may be as well — investors won’t wait for final conclusive evidence to reevaluate how much they are willing to pay for the existing status quo cash flow streams.”
In plain English: ad sales are going down, and fees collected from satellite and cable subscribers are declining. It really isn’t so jarring if you’ve been paying attention to media reporting. The media reporters just usually frame it as slight downward trends. Wall Street frames non-growth as death. Those guys are so fun.
As Mathew notes, Netflix and Google are also down. He speculates that “The Market” has taken it’s anger out on all media. Those guys should sacrifice a small animal, or something.
Josh Rottenberg wrote a piece for the Los Angeles Times comparing Colin Trevorrow to Josh Trank. The first few paragraphs make it read like it really is about the two of them, but then the piece goes in a more interesting direction and speculates about why studios want someone inexperienced for these big tent-pole productions.
Both directors were caught up in a trend that has gathered steam in recent years, as studios have been increasingly looking to untested directors to helm high-stakes tent-pole movies. Most recently, in June Sony Pictures and Marvel Studios hired Jon Watts to take over the “Spider-Man” franchise on the strength of his minimalist thriller “Cop Car,” which Watts shot in his rural Colorado hometown for just $800,000.
Sony did something similar already, when they hired Marc Webb to direct the Amazing Spider-Man reboot, and brought him back for the sequel. Sort of a mixed bag there. If you scroll down to the bottom of the LAT piece there’s a “Nine young directors who’ve made the leap from small films to blockbuster projects” list that even highlights Marc Webb in spite of the text above discussing the new fresh-face being brought in for the Spider-Man franchise.
So many factors but one that doesn’t typically get brought up is the fact that many films are made after the footage has been shot. The old joke “we’ll fix it in post” is something everyone’s heard before.
“The studio executives and marketers want to control the movie so badly, they don’t want a visionary director,” says one high-ranking talent agent. “They want to basically make the movie themselves. So much of it is made in CGI now anyway that you can fix it if it’s messed up, so they can get away with a lot more mistakes. And they don’t really care about deep performances from the actors — that’s not really what they’re looking for.”
I can’t speak to this from any tentpoles I’ve personally worked on, but it’s not unreasonable to assume that this is a possible explanation for entrusting unknown directors. Re-editing sequences, flopping plates, stitching two plates together, omits, reshoots, and completely animated shots that can be tweaked until 1 month before release.
Colin notes that he didn’t experience that on Jurassic World but Trank, in his deleted tweet, does lay the blame at the feet of studio meddling. It’s possible the executives at one studio don’t intervene like they do at another, or that they only step in if they (the suits) perceive a problem. (Whether it’s warranted or not.)
As an audience member, I frequently wonder how a studio went along with a director’s impulses, but I also condemn a studio interferring with the artistic intent and making a movie by committee. It’s kind of hard to reconcile these opposing views.
The article even touches on gender for a bit. Noting that inexperienced men are getting these offers, and there doesn’t seem to be the same happening for women. Colin chimed in with a theory that the many women are turning down the opportunities offered to them — LAT highlights Ava DuVernay turning down Black Panther. I’m not sure that I would really focus on her turning that down as an example that women just don’t want these jobs.
In any event, it’s worth thinking about what’s in Rottenberg’s article.
This past week was SIGGRAPH, a yearly event held in different cities. The last LA one was in 2012, so it’s been a while since I’ve been.
I half-jokingly suggested to Dan that would we meet up at SIGGRAPH and tour it like other podcasters do with CES or WWDC. One of our favorite podcasts (we’re podcast fans too) had a comedy bit poking fun at people constantly asking other people, “How’s your CES?”
Then, before I knew it, we had plans in place and Dan was coming to LA, I was taking a day off work, and we were making silly jokes.
It was such a busy week I haven’t even had the chance to reflect on it until now.
Tuesday, I had to drop off my car (some jerk hit it when it was parked) and pick up a rental, work a day, drive to downtown (turns out there was a Dodgers game causing traffic!), go to a Ringling College of Art and Design event, stop by the bar Dan and I selected for the meet up, and then meet Dan in person in Little Tokyo. I found out at the bar that they had a membership policy, so I got to worry about that, and I had a nasty aftertaste from a margarita and a mojito, so I took a little travel-sized bottle of Listerine I had with me to meet Dan. I spit the mouthwash into a planter just in time to turn to Dan waving to me. I’m not sure how the day could have gone any smoother.
The next day, I met Dan again, picking him up from the LA Hotel (weird name, right?) I put Dan in charge of getting us to the downtown Blue Bottle Coffee (formerly Handsome Coffee). This didn’t work out because Dan’s phone thought he was in Arizona still. Good thing we were in Downtown Los Angeles where the streets are so easy breezy. Ha. We got there, got our coffee and headed back to The Los Angeles Convention Center.
The LACC is a sprawling complex of buildings, with various halls and parking garages. The LA Auto Show uses up the whole thing and there’s frequently plenty of people parking in the private lots around the center. Not for SIGGRAPH this year. Everything was closed up except one garage. Hardly any foot traffic around the building. If you were passing by the buildings, you would assume it was closed.
Making our way to pick up or passes was also strange. In years past, the registration has been in rooms, or in the lobby, downstairs. This year they crammed it next to the “Art Gallery” section. Dan and I had “Exhibition Only” passes which didn’t include the brightly colored, VR-tastic area so we walked back to the main show floor.
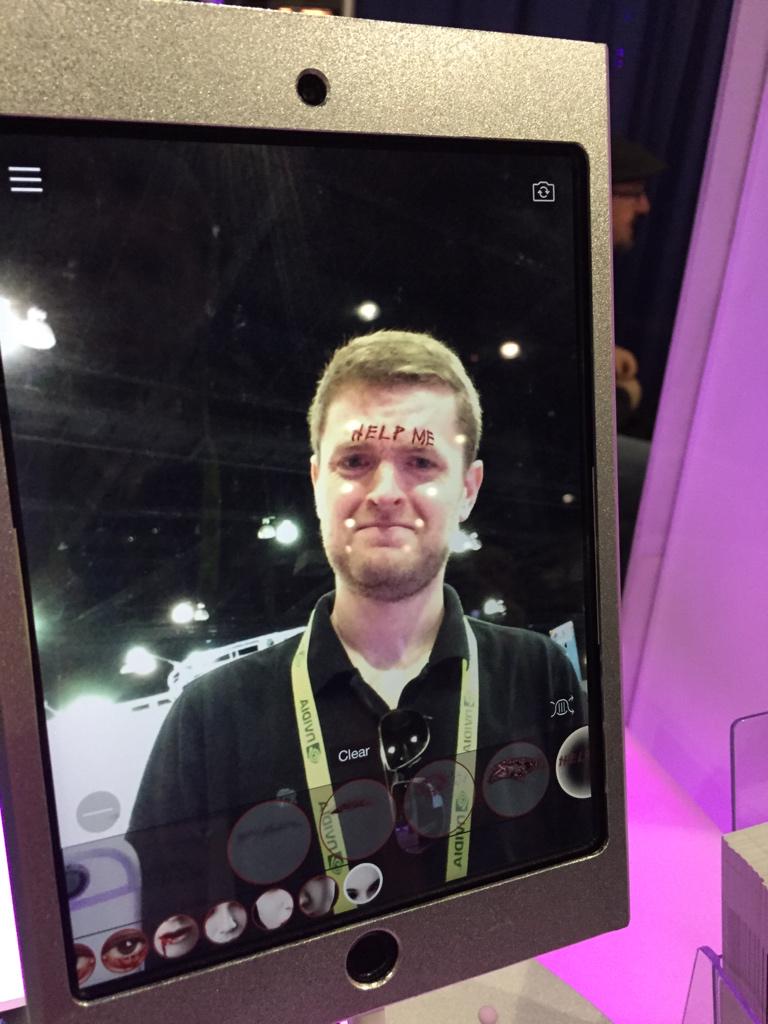
So small. Not only were there fewer companies on the floor, but each company dialed back their elaborate booths. Areas had little stands with cloth curtains to sort of shrink in the space (so it didn’t look like a void with a few stray booths). It was pretty depressing and it took hardly any time to walk the show floor to survey what was on offer. Some booths were just a table, others had tables and some demo stations of different products, like Image Metrics which would track bloody wounds, or makeup, on to your face in real time.
A few booths had space for presentations, with some chairs or benches, and large screens. Dan and I witnessed a few of the presentations, but it was all fairly auto-piloty, with slideshows, or sped up movies of workflows.
The Foundry hosted some nice ones for Mari with two texture painters from a video game studio, and another with a presentation from Tippett Studios about how they used Katana and Nuke to quickly execute a sequel project in half the time as the original. (Videos of the booth presentations are available on The Foundry’s site, but it does require creating a login to view them.)
There were some presentations in little rooms upstairs, but the schedules weren’t posted anywhere Dan and I noticed until we wandered up there. By then it was mostly for topics we did not have an enormous interest in.
Even though it was Wednesday, of a week long convention, it seemed to be winding down. Most major things seemed to have happened Monday or Tuesday. I certainly wouldn’t book a week to attend, unless I was some big head-honcho. A Renderman “Art and Science Fair” was scheduled for that night, but it ran for several hours and would have consumed the limited time Dan and I had (besides, neither of us use Renderman these days). Renderman did seem to be the biggest draw, but mostly because people are interested in Pixar (the line for the walking teapots was so long).
We went back to Dan’s hotel, recorded half of a podcast episode wrong, and then half of a podcast episode right. Listen to Episode 59 here.
We grabbed some dinner at a pretty lackluster restaurant (rounding out a full day of pretty unexceptional dining) and finally sorted out how to get people in to the membership-required bar (Dan and I are both members of a rum bar now.) One of the podcast listeners that came to the event even went to SIGGRAPH, but I continue to be fascinated by the listeners we have that enjoy the show regardless of all the inside-baseball stuff about VFX nerdery. Very thankful for all the listeners, even those that could not make it.
Reflecting on the whole thing, I came away with a pretty negative impression of SIGGRAPH 2015. It doesn’t seem to service artists a whole lot, and seems like more of a corporate networking event. Even the job fair section shriveled up and tumbleweeds blew through it. Although Imageworks had a big booth, they were hiring for Vancouver, which still hurts. I wish the people I know there well, but I’ll never be able to work there again. Seemingly none of the other companies were all that interested in LA either. Dan got a free mint though.
Incongruously, there is a ton of cool stuff that comes out of SIGGRAPH. Papers, presentations, software, etc. It mostly affects you if you’re lucky enough to work at a company that can take advantage of these advancements. Or even companies that have R&D budgets. I encourage everyone, regardless of their chosen discipline to check out the work. Stephen Hill from Ubisoft in Montreal is collecting links and putting them up on his blog.
Seriously, go look through all the amazing stuff people make that you won’t see on tech news sites.
However, if you would prefer to digest this through a news site, I would recommend fxguide, which had a number of people covering it in great detail. Day one, day two, and day three.
The industry I work in sure has changed a lot in the three years since I last attended one in LA, and I was confused about why they even bothered to have it in LA at all this year, let alone Anaheim next year, and LA again the year after that. Sony Pictures Imageworks’ move to North made Vancouver the largest concentration of VFX workers. Sure, there are small places, like my current employer, as well as Disney Animation and DreamWorks, but it hardly seems like a thriving community with high morale. Video games seems to supplement some of those motion picture losses. But they mostly seek out engineers, not artists. Same for VR.
Would I attend another? Sure. Who knows, maybe things will turn around for people in my particular position. Barring that, I’ll at least be able to document it’s steady decline. Yay.
At least I have the podcast with Dan, people that enjoy it, and some neat projects to look at.
One of the things that I’ve started to question about Apple’s media strategy is how they approach the big power brokers and aren’t fostering a new, independent wave of content creators.
YouTube provides space to work, and collaborate in several major cities for channels with at least 10,000 subscribers. It’s so popular the summer signup period is full, and people have to check back after September 1st. They even offer classes, but they’re full, and they require 500 subscribers to qualify. (Which seems pretty weird for classes on getting started.)
Apple doesn’t have an education program like this. You can sign up for iMovie classes at a local Apple Store, or you can search [iTunes U for a class] that will cover the skills.
People don’t need courses, or fancy studios, or very specific software instructions in order to make video, or upload it to the internet. Creating a focused community around a type of media, and supporting that work, will foster the specific kind of content a company would like. That sounds so cynical, and unartistic, but only when viewed from very far away.
Anyone can start a YouTube channel and upload video. Connect currently requires an artist to be selling music through iTunes, which makes sense since it’s about promoting material on iTunes, but if there was Connect for TV and film, it’s worth checking out what it takes to sell a TV show (most analogous to a vlog series):
The requirements to work directly with Apple are listed below. If you do not meet all of these requirements, you can work with an Apple-approved aggregator instead. Aggregators are third parties that can help you meet technical requirements, deliver and manage your content, and assist with marketing efforts.
Technical Requirements:
* iTunes does not accept content in physical formats like VHS, DVD, etc.
* You must deliver your content as a digital file through one of the Apple-approved encoding houses. Be sure to compare their services and fee structures, as this will be a separate cost if you work directly with Apple. Appropriate file storage capability and bandwidth is also required. Alternatively, you may work with an Apple-approved aggregator instead.
* All video content must be stored in Beta SP format or higher. iTunes only sells video content that is DVD-quality, so the quality of your source must be significantly higher than a standard definition DVD.
Content Requirements:
* At least 50 hours of network-aired TV content
* Digital distribution rights for all content you intend to sell on the iTunes Store
* All associated music and talent rights cleared for digital distribution
Financial Requirements:
* A U.S. Tax ID
* A valid iTunes Store account, with a credit card on file
* Apple does not pay partners until they meet payment requirements and earning thresholds in each territory. You should consider this before applying to work directly with Apple as you may receive payments faster by working with an Apple-approved aggregator.
Note: Meeting these requirements and submitting an application does not guarantee that Apple will work directly with you. You may still be referred to an Apple-approved aggregator.
So just get a network TV show, use an approved encoding house, or figure out the aggregators, and you’re all set! Easy peasy!
Compare that with signing up for YouTube uploading a video.
Indeed, even signing up to distribute a podcast (and dealing with XML validation!) seems far more manageable. What if there was a Connect for Podcasts? Well… they’d need to figure out some kind of revenue stream to compete with YouTube, because ‘free’ wouldn’t cut it.
Oddly enough, artists can upload videos, and audio, as part of Connect posts that aren’t part of the iTunes store. Unfortunately, you can’t go back and find those things later because they don’t appear in search results, only from scrolling through the Connect stream.
As for growing a “brand” — It’s a one-way broadcast tool. There are comments, but they’re tucked away. They present in a chronological list, and there’s no pinning, emphasis, threading, or promotion that can be applied. It’s like traveling back in time to 2000. Looking at the comments is just sad.
Connect is clearly for the already established to announce things. They might as well turn off the comment feature.
I mentioned “the established” but it’s not just referring to the already successful stars, directors, and musicians of the world, but the studio systems that support them. Indeed, much of that media might is held by a small group in Los Angeles. They’re pretty old, and not particularly in touch with the youth of today. They control content deals, and they’re the reason why “progress” gets tied up for an eternity.
Apple wants the established media, instead of fostering independent creation, and the established media doesn’t want to give an inch. They might be less, and less powerful every year, but they can still cling to it to prevent a disruption in the business of buying (leasing), and collecting (please lease it again when there’s a new format).
It seems practical for Apple to invest in independent content creators, like YouTube has, and continues to do. They might find themselves in the unenviable situation of only needing Hollywood.
The Verge published a piece on August 4th titled “2015 is the year of Hollywood’s practical effects comeback”, but I mercifully remained ignorant of its existence for four days. This is another long, rambling post about how “practical effects” are good, and “CGI” is bad. You know, the kind of article that sounds very appealing on the surface because it talks about how much better things used to be, and how bad things are now. I am particularly irked that these poorly reasoned opinion pieces get broadcast to large audiences. It’s one thing if someone wants to tweet this, it’s another thing if a journalist uses his platform to broadcast things that aren’t accurate. It makes the discourse worse when that happens.
The reason it happens is because writers don’t know enough about VFX, which makes that black box an easy target. It’s whatever’s in the mystery box that made the movie bad.
The same day Kwame published his piece, Freddie Wong put out a great video that undercuts these sort of arguments. The timing is coincidental, but the subject is the same. Freddie’s video is a great way to demonstrate the flaws with “CG Sucks”. It’s not without flaws, but it’s my number one choice to refer people to.
The computer is a tool, and some folks know how to use it well while others don’t. It doesn’t make the tool bad when it’s used gracelessly, and we have to improve the conversation about how special effects are used in modern media … especially when we don’t even know they’re there.
I’m going to go through Kwame’s opinion piece and break it down. It’s not the nicest way for me to spend my time, but I don’t want to leave any lingering doubts that this sort of film critique isn’t helpful, and it’s damaging to the public perception of what I do for a living.
The biggest set piece in Mission: Impossible — Rogue Nation is also its first scene. We’ve all seen it in the trailers: a frantic but determined Ethan Hunt (Tom Cruise) clutches the side of an Airbus A400 for dear life as it takes off into the stratosphere. While the scene itself is only tangentially related to the overall plot of the movie, Paramount made sure this was the scene that got people into theaters. A large part of this strategy was broadly publicizing the fact that it wasn’t faked. No CGI was used. No expense was spared. Tom Cruise was really and truly strapped to the side of that plane.
Here we see the first problem. If Paramount had not promoted this as being a real stunt, then no one would know it was real or if computers were used to augment reality.
Indeed, computers were used to augment this very scene and remove the wires used to safeguard Tom Cruise’s life. Wire removal is still a visual effect, and it’s not a flashy one because you’re not supposed to see it. It is an invisible effect.
The Mission: Impossible franchise decided long ago to place its bets on over-the-top stunt work — Cruise famously scaled an actual section of the Burj Khalifa in Dubai for Mission Impossible: Ghost Protocol in 2011, for example. But in 2015, practical effects and stunts aren’t exceptions to special effects rules. As some of the biggest movies of the year — namely Rogue Nation, Mad Max: Fury Road, and the upcoming Star Wars: The Force Awakens — rely more and more on real-life actors for their action scenes, we might be seeing the start of a shift away from CGI as practical effects become a bankable alternative.
First of all, he is citing a film no one has seen as an example of practical effects being used well. Secondly, he speculates about real-life actors being used for their action scenes more often. That has nothing to do with practical effects. In the old days, stars would perform their own stunts, on occasion, if it could be safely executed because there was no technology to do face replacement for stunt doubles. Sometimes, you’d just see a stunt double! Digitally replacing someone’s face, or putting an explosion behind them, isn’t inherently worse. If Paramount has not told everyone Tom was really on that plane then no one would have known because visual effects artists can believably pull that off these days. You could say that it would totally fly under the radar.
As far as “bankable” goes? Marketing select stunts as practical might be novel, but it’s not a distinguishing feature of the film as seen on the screen.
There’s certainly no question that CGI can take fantasies and make them seem like reality on the big screen. Recent successes like Furious 7 and Avengers: Age of Ultron wouldn’t be possible without computers allowing for flying suits of armor and cars flying out of buildings. But after more than a decade of high-octane CG theatrics from huge box office juggernauts like Transformers, Harry Potter, Avatar, Star Wars, Star Trek, Terminator, literally anything the Wachowskis make, and every Marvel and DC tentpole, audiences might be getting fatigued of digital models exploding into countless pixels. As Variety TV columnist Brian Lowry put it after seeing Age of Ultron, CGI can now prove “more numbing than exciting, even during what should be the show-stopping sequences.”
Kwame, and Brian incorrectly blame a writer, or director’s injudicious use of a tool to mean that the tool itself is flawed. Killing a large number of nameless, meaningless things – whether digital or practical – will always be hollow regardless of the means used to execute the effect on screen.
Groot was a digital character in Guardians of the Galaxy and people loved him. They felt bad when bad things happened to him. In the same film, there are waves and waves of people dying and it means very little. If a computer didn’t touch those scenes it would read the same, emotionally, it would just cost a ton of money to manufacture. If any journalists would like to spring into action and second-guess the things Hollywood spends money on, go for it, but that’s not this argument.
Hollywood’s reliance on CG has only intensified. In the 1970s and ’80s, movies like Westworld and Tron made use of rudimentary computer graphics to dazzle audiences who’d never seen such worlds on the big screen.
Really? That was the perfect execution of computer graphics in film? Westworld and Tron? They should have just held steady there?
Again, this wouldn’t read as a better experience with stop-motion robots. Maybe, just maybe, Transformers: Age of Extinction might have issues with story and direction?
As computers have gotten more powerful, studios have used them to create bigger spectacles. Bigger spectacles translate to bigger box office returns; according to Box Office Mojo, six of the top 10 highest grossing films of all time were CGI-fueled summer epics that came out in just the last five years. Three came out this year alone. Raising the stakes for what what we expect from our popcorn fare inevitably means upping the visual ante. That’s not necessarily a bad thing, so long as it’s done well. But in overindulging what it thinks is our bottomless appetite for bigger, more bombastic movies, Hollywood might be battering our senses to the point of dullness.
Huge factual errors here because it assumes the films are successful because they used digital effects. Even the most mundane projects use digital effects for set extensions, a couple sky replacements, makeup fixes, wire removal, painting out camera reflections – Lots of stuff. It is a part of filmmaking.
Also, if spectacle was inherently successful then all expensive, VFX-driven films would be successful. That is not the case. Even Disney, which has some of the biggest successes, with VFX out the wazoo have had very expensive flops. Sadly, Tomorrowland was not well received this year, and that was “done well”. It had nothing to do with “dulled senses”. Pixels, and Fantastic Four are loaded with effects but didn’t perform as well as other VFX heavy productions.
Spectacle, even if it’s executed well, isn’t going to guarantee the movie is even a financial success. Regardless of it being physical or digital.
Despite their fleeting moments of specialness, “The Avengers,” the “Iron Man” and “Thor” and “Captain America” films, the new “Spider-Man” series and “Man of Steel” treat viewers not to variations of the same situations (which is fine and dandy; every zombie film has zombies, and ninety percent of all westerns end in gunfights) but to variations of the same situations that feel as though they were designed, choreographed, shot, edited and composited by the same second units and special effects houses, using the same software, under the same conditions. As long as people are talking, there’s a chance the movies will be good. When the action starts, the films become less special.
In other words, all this is expected, and the miracles that cinema pulled off 30 years ago — the moments when audiences felt transported to the directors’ dreamscapes — now feel rote.
This has nothing to do with using a computer to make images on a screen. This has to do with the images that get approved to go on that screen at the whims of the director. It has nothing to do with specialness of the tool.
It should really be pointed out that people make computer generated effects. A computer, by itself, generates nothing. If that were the case, your home PC would be pumping out Pixar classics while you browse the web for new shoes.
Just as people made miniature models to blow up, or painted matte paintings, or drew lightning by hand. People have to make it happen.
But in recent years, there’s been an attitude shift bubbling up among some of Hollywood’s biggest-budget filmmakers. In a recent interview on The Tonight Show Starring Jimmy Fallon, Rogue Nation co-star Simon Pegg talks about the merits of dangerous stunts over CGI:
“These days,” he says, “CG is an amazing tool, and we love it and it enables us to do amazing things. But when you see something which is digital, there’s a slight sense of disconnect. You know it’s not real. Tom taped himself to the side of a plane for real! That’s how much he cares about you!”
What Simon Pegg is describing is when he knows something isn’t real. That means the effect didn’t work out. You can also know that animatronics, stop motion, matte paintings, and optical lightning are in a movie and they’re not “real”. Go watch Arnold take a table-tennis-ball-sized tracking device out through his nostril in Total Recall – or basically any effect in that movie. Tell me how real it feels.
There actually is a visceral sense of danger and even wonder as you’re forced to acknowledge that a human being is risking their life for a film, much in the same way that there’s a greater feeling of connection to a person in makeup over her CG counterpart.
Only if you know they did. The goal is that you can’t tell whether or not they did. It is so very easy to highlight effects that did not work, but it is hard for audiences to perceive the ones that did. Freddie Wong’s video highlights a couple examples that are worth considering, but if you watch enough behind-the-scenes videos you’ll see plenty of other invisible effects.
That’s certainly true for Mad Max: Fury Road, whose promotional push made much of the fact that it was shot in the Namibian desert with real cars, real explosions, and a real flamethrowing guitar, as if to remind people that things like that could still be pulled off in real life. Of course, director George Miller also used plenty of digital effects to push his scenes over the top. Of the film’s 2,400 shots, 2,000 of them were VFX shots. But set pieces that might have been done purely by computer in other movies were choreographed in real life, making for some beautiful but incredibly dangerous scenes.
This is where Kwame should have realized his whole argument against the pervasive use of computer graphics made no sense. 83% of a film. No big deal! Not to mention the color grading (digital), the editing and retimes (digital). That is not to belittle the importance of the work performed on scene, but to highlight how this had nothing to do with computer graphics being bad. VFX shots aren’t cilantro.
And it’s especially true for Star Wars: The Force Awakens, which hits theaters later this year. Director J.J. Abrams has continually and consistently paid deference to the practical ingenuity that made the original trilogy so great. So in addition to the return of the original starring cast, we’ve also been promised a return of practical effects. The new X-Wing? Real. BB-8? Real. The Millennium Falcon? So real as to injure Harrison Ford on set. These decisions are billed as a return to form, as a chance to go back to the way things are supposed to be.
Not to beat a dead horse, but the movie isn’t even out yet, the marketing push is. Also that list is wrong, because the Millennium Falcon as a set piece is real, but that ship you see flying around sure as shit isn’t. Those “X-Wings” are real set pieces but they aren’t models over that water.
Don’t give me this “real” stuff about a space movie in a galaxy long, long ago that was part of a $4 billion sale to a media conglomerate. It’s about illusion. It’s great that a person might think it’s real, but it’s about the suspension of disbelief, not physical manufacturing. Physically manufactured elements can help, but it’s not like anyone believed the puppet Yoda in The Phantom Menace was real, in spite of it being a physically manufactured puppet. (Except for the walking part.)
And that’s likely the whole point — that striving for verisimilitude today means moving away from the CG that’s an industry standard and reminding audiences of how directors like Spielberg and Lucas did it way back when.
No, no it isn’t the point at all. Film is not a documentary process. Truth is belief, not reality. Use the writing, acting, makeup, costumes, stunts, sets, locations, color grading, editing, special effects, and visual effects that make the audience get swept away in the story.
It’s clear that, at a time when so many of today’s movies are reboots or returns to older properties, studios are trying hard to mine for what made people feel so good about going to the movies in the first place. Directors like Abrams and actors like Tom Cruise seem nostalgic for a time when connecting to magical objects, spaceships from far-off galaxies, and actual peril meant relying on props, makeup, wires, and daring. They’re both saying that today’s CG landscape can’t pull that off because we take computerized effects for granted.
No, I think they did it this way because they thought it would work for the movies they were making. Again, it bears repeating that the Star Wars movie has not been seen by Kwame. He’s immediately lauding it for practical effects.
That doesn’t mean that practical effects are inherently better or that CGI shouldn’t ever be used. It just means that, like music lovers preaching the gospel of vinyl, some directors are pushing back against CGI because practical effects express their ideas about how their particular movies — and maybe movies in general — ought to be made.
What?! A whole slew of words about how computer graphics shouldn’t be used and we come to an analogy about vinyl? Vinyl?!
I anxiously await the print edition of The Verge on my local newsstand, because paper is an inherently better medium.
At the end of the day, though, Mission: Impossible — Rogue Nation is just a popcorn flick, diverting but ultimately empty.
“Anyway, I think practical effects make movies good but this movie wasn’t good, so oh well.”
Special effects can never replace the connection created by an excellent story that keeps you invested from start to finish. But you do feel something during those stunts, an elevated kind of thrill knowing Tom Cruise really is on that plane or on that motorcycle, risking his life so that we can have fun for a couple of hours at the movies. It could be argued that Rogue Nation would be no better if the whole thing were done with green screen.
I will gladly argue this. In fact, I have, above. Kwame’s time would have been better spent arguing this as well.
After all, real-life action gets our attention right now primarily because it feels so different.
It doesn’t feel different. It has been marketed as being different. No one A/B tested this movie with a version heavier on computer graphics. There was no Pepsi Challenge.
But with the next few years positively glutted with action movies, “different” might have a leg up on the competition.
In marketing films it might give the project a leg up on competition by virtue of the fact that audiences have been fed a narrative that one kind of illusion is inherently better for them, in all cases, than another kind of illusion.
Richard Lawson (yes, that same Richard Lawson that posted baseless rumors for Gawker) went to VidCon for Vanity Fair to write about the conference, the fans, and the stars. Also the business of why they are famous. For anyone struggling to wrap their heads around the popularity of YouTubers, Viners and other influencers then this piece is for you.
Like I usually point out, and Richard also points out, it’s very easy to roll your eyes at all this, but then you’re ignoring a significant shift in the way money is changing hands for entertainment.
And with that change comes big dollars for these influencers. After our second meeting, Talavera and Leimgruber followed up with an e-mail that included some hard numbers. What they had to tell me: approximately 200 social-media influencers have earned over $1 million in the past year, and another 550 earned more than $250,000. The NeoReach guys estimate that the number of “Millionaire Influencers” will double next year. Popular YouTubers (1 million-plus followers) can earn as much as $40,000 per video, and $5,000 per Instagram post. That money is coming from sponsorships that pay out $0.05 to $0.10 per YouTube view, or $0.15 to $0.25 per Instagram like. Add on top of that the money made from Google AdSense, and any merchandise sales and appearance fees. In short, these people, and there are many of them, are getting very rich.
With all that money changing hands there are also problems. Richard describes the despair he felt at the parties. Even the concerns that some of the “older” YouTube stars like Grace Helbig and Felicia Day have for these kids thrust into sudden fame and fortune.
I’d also like to add that part of the reason it’s so difficult for non-teens to understand the celebrity of these YouTube stars is because we feel creeped-out by it.
I read Richard’s piece after Marko Savic had sent me Caroline Moss’ profile on Vine star Logan Paul. A very distilled look at a specific person in this sphere which was also interesting.
Update:I was contacted by Richard Lawson about my description of his past work at Gawker. I used the words “fabricated lies” but he wanted to point out that he never made up anything, just ran rumors. I’ve adjusted the wording to reflect that. I still find repeating baseless rumors of abuse irresponsible. Though his past writing isn’t relevant to the VidCon story, I am still bothered by it.
Seriously, go watch the cute video done in that 50s-Disney-educational-cartoon style. Never has path tracing and ray bundling been more appealing. Literally, never.
There’s further explanation, and some swippable demos there as well. The linked PDF is also available for the very-very curious.
There are many similarities between this renderer and Arnold, which I used at Sony Pictures Imageworks.
I know that many people find the complaints around Apple Music tiresome, but I’m not complaining because I hate it. If I hated it, I wouldn’t talk about it at all. I certainly wouldn’t spend any time trying to improve my experience with it, or writing about my experience in the event my troubleshooting helps someone, or someone can provide advice to me.
The problems break down in to recommendations, UI, social, uptime, and data loss. All of these can improve over time, and hopefully will improve quickly. There is a lot that Apple Music already has going in its favor, such as editor playlists, and a vast content library at your fingertips.
I’m just going to go over issues with data loss in this post to keep it focused. Specifically data loss due to iCloud Music Library, which is a cloud service, and not your iTunes Library, which is the local data on your computer.
My iTunes library has some albums that are from polymer circles people used to buy at physical stores. Those not-from-the-iTunes-store albums seem to be the central issue for people experiencing problems with metadata on their tracks changing. Album art, album versions (particularly greatest hits), tracks (live recordings vs. studio recordings), etc.
When Apple’s quiet service changes something in a user’s iCloud Music Library some of the changes affect local copies of files (my queen songs were already on the device when it reorganized the albums and album art). Other changes only affect what happens if a file is no longer on your device, or was never on the device, and is downloaded. You might get the wrong file. This happens in ways that are not always reproducible.
That’s really concerning because then you’re just rolling dice. You open the app and something’s missing, or changed, and you’ll have no idea how long it’s been that way. If that wrong data has migrated to all your backups, or if it just happened a minute ago.
Another kind of data loss is missing playlists. I first saw Anthony Waller point this out on Twitter this morning. Then I said to myself, “Oh that sucks for him, I know my playlists are there because when I opened this the other day — OMG WHERE DID MY PLAYLISTS GO?!” Indeed, all of my playlists that were not created after my iPhone was updated, and the iCloud Music Library were enabled, were gone. That left me with “Purchased”, like Anthony, an Apple Music editor’s playlist I saved, and “Star Trek” — because I’m a super cool guy.
The playlists were all still there on my MacBook Pro. When iTunes 12.2 found its way on to my Mac, I didn’t enable the iCloud Music Library like I had on my iPhone. This isn’t my first rodeo. I use my Mac as an organized repository of collected works — you know, like a library — and I thought caution was appropriate. Turns out that was a really good idea!
Apple has provided no way for users to revert changes that are being made in iOS, and no mechanism to recover deleted data. That really bothers me because if an automated system is going to make changes to optimize my data then it’s never going to be 100 percent accurate. Dropbox is really close to perfect these days for maintaining the integrity of my data, but they still have mechanisms to recover files and revert versions.
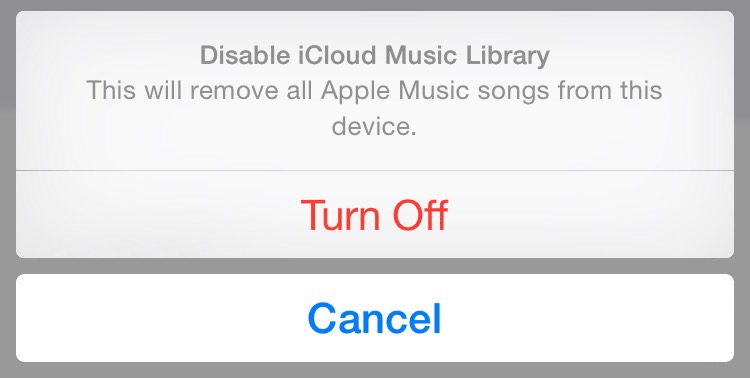
My iPhone would not sync with iTunes. When you have iCloud Music Library enabled on your phone, it disables it and cheerfully reminds you that all your music lives in the cloud — the place where it’s totally safe and stuff. So obviously the software engineers didn’t think you needed to manually sync anything.
Disable iCloud Music Library on the device.
Settings > Music > iCloud Music Library toggle.
Backup the iCloud Music Library on your computer. Just in case!
File > Library > Export Library …
Sync your iPhone with your computer.
Check both libraries.
Optional: Don’t reenable iCloud Music Library
Some might find this too paranoid, but really it’s just laziness. I know I have the data, I’m not sweating bullets over that, I just don’t want to repeatedly have to restore things. You can use Apple Music just fine without iCloud Music Library. Most people might not know that. The tracks all download offline, the playlists work, everything. It’s just about keeping the “My Music” section identical on all the devices without user-initiated sync. That includes keeping the things you’ve “hearted” in sync to improve recommendations.
Since reactivating iCloud Music Library would probably cause random, quiet, data loss I’m just not sure it’s worth the effort. Like I said, it’s a bigger waste of my time to purge problems than to keep it up-to-date.
Whether or not you turn it back on, it’s pretty clear that this isn’t an optimal user experience, and it further tarnishes Apple’s reputation with cloud services. I would really like a bright, and gleaming reputation. You know, a silver lining…
The Hollywood Reporter might be misusing the word “daring”, but Paramount does have a unique plan to reduce the window between theatrical release and on-demand release. The agreement only covers some films (right now, it’s two horror films), and there’s still a small window of theater time. When the number of screens showing a movie drops below a threshold (300) then Paramount can release it through video on demand services in as little as 17 days. The theater chains receive a share of the profits.
“This is all about changing the definition of theatrical windows. Instead of starting the countdown from when a movie opens, we are starting from when it ends,” Paramount vice chair Rob Moore told The Hollywood Reporter when the deal with AMC and Cineplex was struck.
Big movies, like Mission Impossible: Rogue Nation aren’t part of this. People are willing to go see those kinds of summer blockbusters, and everyone would love to protect the profits in that window.
This could be a way to make more mid-budget pictures in the future, if they can be quickly moved to digital, on-demand markets, and out of the high-stakes opening-weekend races.
The device itself is pretty much as we described it to you in March, sources say, but “more polished” after some additional tweaks. Expect a refreshed and slimmer chassis and new innards; Apple’s A8 system on chip; a new remote that sources say has been “drastically improved” by a touch-pad input; an increase in on-board storage; and an improved operating system that will support Siri voice control. Crucially, the new Apple TV will debut alongside a long-awaited App Store and the software development kit developers need to populate it.
Maybe Apple’s just trolling everyone at this point?
Curiously, John’s sources say that the OTT service will not be unveiled at the same time.
When rumors of the rumored unveiling were last destroyed via a leak to The New York Times, the blame for it was placed on the content partners not cooperating on the OTT service. (Specifically, trying to get local broadcast stations onboard, not just national networks, and studios.) As I’ve repeatedly argued, there is plenty of justification for upgrading the device even without the OTT service.
Obviously, if this rumor is true, and the device ships without an OTT service, it can only mean that Apple Executives love reading my blog. No other conclusion, really.